
Muy buenas!
Hoy os traigo un post sobre como crear un clúster con proxmox paso a paso. En este post verás como se añaden los nodos al cluster y como se añade el datastore ceph para todos los nodos.
Requisitos para hacer un cluster con proxmox (según recomendaciones de la web del proyecto):
- Al menos 3 nodos en el clúster (por el quorum de proxmox). Para realizar acciones distribuidas proxmox necesita aprobar mediante los votos de cada nodo esta acción.
- Datastore replicado en los nodos para las VM y los contenedores.
- Redundancia de hardware (discos, servidor, controladoras de red, etc).
- Todos los nodos se tienen que poder conectar entre ellos via los puertos 5404 y 5405 UDP para que corosync funcione.
- La fecha tiene que estar sincronizada.
¿Cómo funciona la alta disponibilidad de proxmox a bajo nivel?
Al crear el cluster, proxmox lo hace con corosync, una herramienta que permite hacer alta disponibilidad entre diferentes aplicaciones y la creación de clusters.
Si hacemos un systemctl status corosync, veremos como está el servicio activo y con los 3 nodos que configuraremos mas adelante.
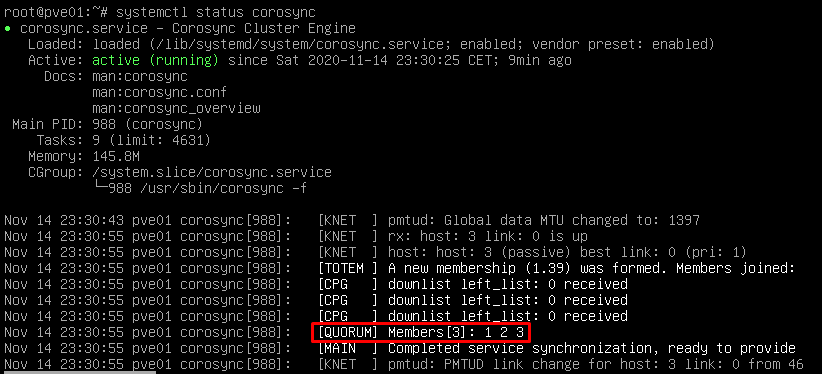
En cuanto al HA de datastore eso ya será nuestra decisión si utilizar ceph o nfs o lo que queramos, en este post os enseñaré ceph a nivel básico.
Entendiendo ceph y el quorum
Antes de ponernos a hacer el clúster creo que es buena idea dejar el concepto de lo que es ceph y como funciona y el concepto de quorum.
¿Qué es ceph y para que me sirve?
La diferencia principal entre NFS y ceph es básicamente que cepf es descentralizado, al ser un storage en forma de objetos almacena la información distribuida en cada uno de los discos que conforman ceph. Con NFS simplemente es centralizado y a la que cae la cabina o el recurso NFS se va todo al garete a no ser que tengamos un segundo NFS con replicación entre ambos.
Ceph utiliza el algoritmo CRUSH (Controlled Replication Under Scalable Hashing) lo que hace que ceph calcule en que ubicación y en que OSD se debe almacenar el objeto. Con esto ceph puede reescalarse, balancearse y recuperar datos de forma dinámica.
Requisitos de Ceph:
- Monitor: Mantiene un mapa del estado del cluster.
- Managers: Responsable de realizar un seguimiento de las metricas de tiempo de ejecución y el estado actual del cluster de ceph.
- OSD: Almacena datos, maneja la replicación de datos, recuperación y balanceo.
- MDS: Almacena metadatos. Los servidores de metadatos de ceph permiten ejecutar comandos básicos (ls, find, etc).
¿Para que sirve el quorum?
En el caso que se tenga que hacer una transacción distribuida por alguno de los nodos o que tenga afectación en varios nodos será necesario un mínimo de votos (quorum) para que sea permitida ejecutar la acción en un sistema distribuido. Proxmox asigna un único voto por cada nodo por defecto.
Preparación de cada nodo antes de añadirlo al cluster:
Primeramente tenemos que instalar el proxmox, una vez hecho esto se le tiene que asignar la IP final que tendrá el servidor y el nombre ya que una vez añadido al clúster no habrá posibilidad de cambiar la IP ni el nombre del servidor.
En este post se puede apreciar que entro en cada nodo y añado la ip de cada servidor en el archivo /etc/hosts de cada servidor, esto no es necesario para que el clúster funcione, sin embargo yo a nivel personal me gusta configurarlo ya que así no me tengo que acordar de la ip si quiero hacer ssh a otro nodo.
Nodo1:

reboot
Nodo2:

reboot
Nodo3:

reboot
Creación cluster:
Para crear el clúster en proxmox tendremos que ejecutar el comando que adjunto a continuación. Este paso se puede hacer via GUI.
pvecm create nombre_clusterVeremos que crea el cluster correctamente

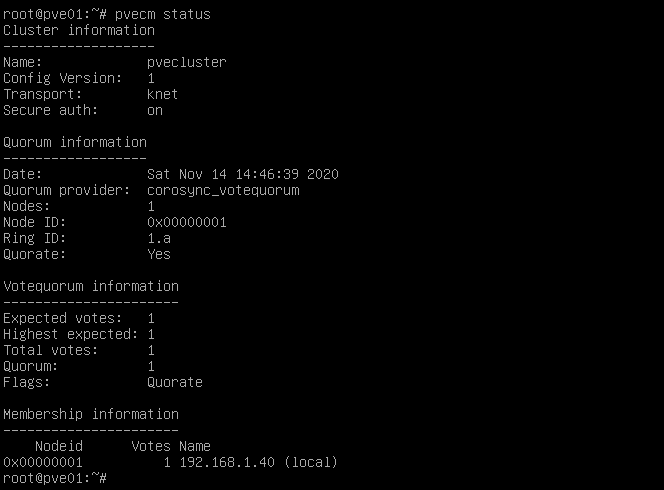
Miramos estado del cluster:
En este paso podemos ver por una parte la información del clúster, los votos que se esperan del quorum, ahora solo hay un nodo añadido al cluster y es por eso que solo espera tener un voto para poder aprobar la transacción.
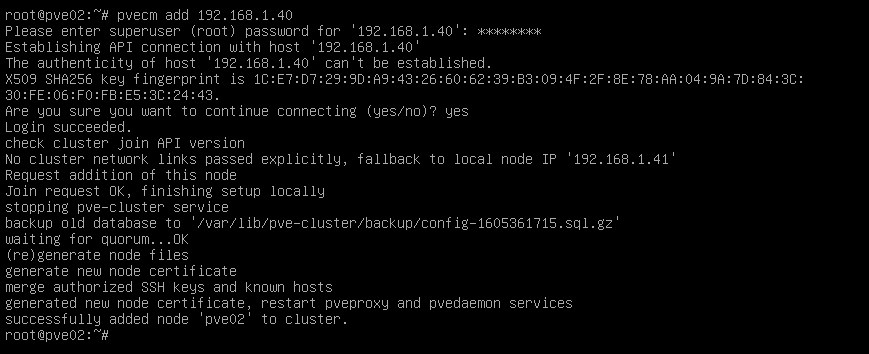
Para poder añadir cada nodo al cluster, tendremos que entrar en cada nodo individual y ejecutar la siguiente orden:
pvecm add IP_NODO_1Con este comando lo que hacemos es decirle que se añada al clúster. El proceso de añadirse al clúster lo hace contactando con el nodo principal mediante SSH, entonces lo que hace es comprovar el código para hacer el join al nodo principal. Este código lo podemos encontrar si vamos a centro de datos -> cluster -> información de la unión y nos mostrará el código para añadirse.
Entramos al nodo 2 y añadimos el nodo 1.
Entramos al nodo 3 y lo añadimos al cluster
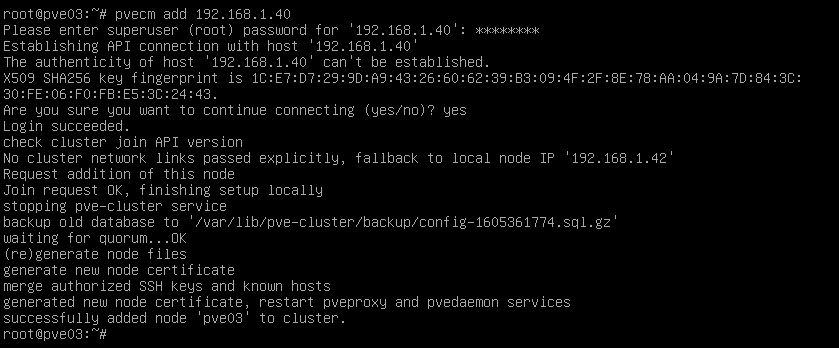
Miramos estado del cluster:
Para verificar que los nodos se han añadido correctamente al clúster lo podremos comprobar con el comando pvecm status y veremos que en quorum information sale que hay 3 nodos. En esta ocasión veremos que en expected votes del quorum ya aparecen 3 votos ya que es 1 voto individual por cada nodo del cluster. Al final de todo podremos encontrar el listado de los nodos unidos al clúster.
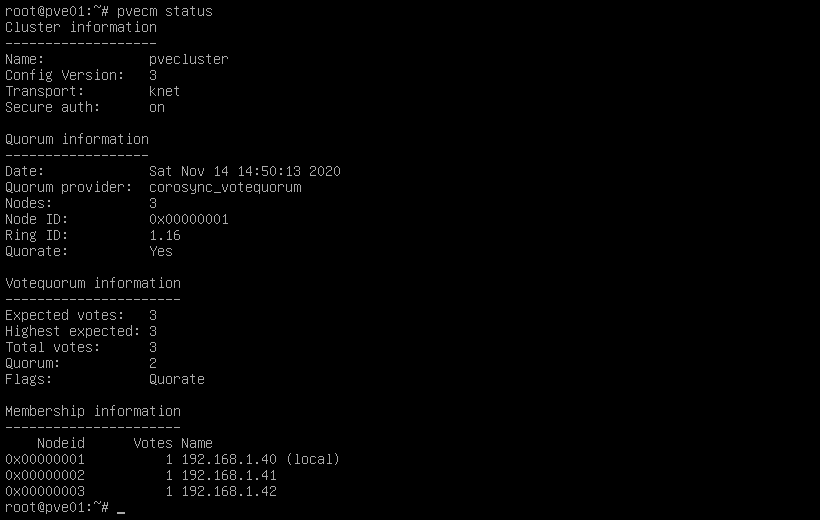
Miramos los nodos añadidos al cluster:

Veremos que si entramos al nodo principal tendremos añadidos los otros dos nodos.
Para verificar que se han añadido veremos que en la parte lateral izquierda nos muestra des de la IP del nodo principal los 3 nodos.
Añadir recurso NFS centralizado al cluster de proxmox:
Para añadir el recurso es sencillo. Especificamos IP del servidor NFS, en ID le ponemos el nombre que queramos, en export le tenemos que poner la carpeta que se esta exportando des de el servidor y el contenido que se puede almacenar en este storage.
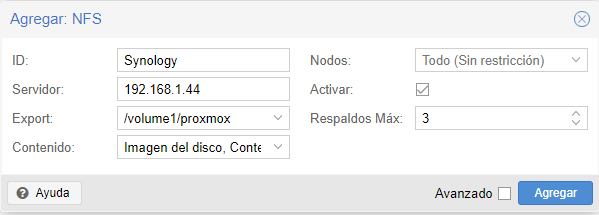
Una vez añadido ya tendremos un datastore compartido entre los tres nodos:
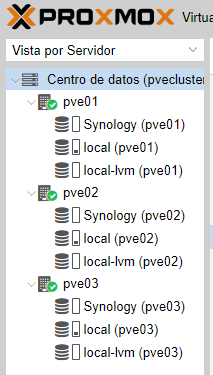
Segundo storage replicado entre nodos proxmox (ceph)
En este caso voy a configurar un segundo storage con ceph para que veáis el proceso y para que veáis que se pueden tener diferentes sistemas distribuidos de storage, supongo que no es recomendable pero es como todo en algun punto puede ser interesante para almacenar x cosa en un storage y x cosa en otro storage.
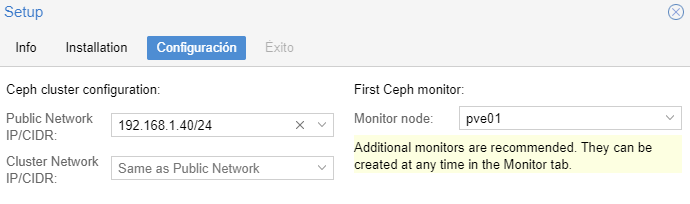
Creamos cluster en ceph:
En este paso simplemente especificamos la IP del nodo principal con su mascara de red. También de paso añadimos como monitor el pve01 (mas adelante añadiremos los otros nodos).
Al sólo tener un nodo como monitor del ceph no nos mostrará mucha cosa.
Añadir segundo nodo a ceph:
Para añadir el nodo cabe recordar que previamente se tendrá que instalar el ceph y activarlo y luego se tendrá que ir a ceph -> monitor y crear.
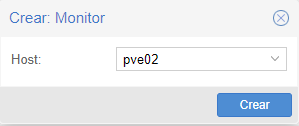
Veremos que una vez añadido ya nos muestra la dirección IP, el estado y la versión de ceph y que a su vez estan instalados como monitores.

Una vez hayamos añadido los 3 nodos quedará así:

Crear OSD:
Para añadir un disco duro donde ceph pueda almacenar estos datos será necesario que añadamos un nuevo disco preferiblemente del mismo tamaño a cada server.
Añadimos un nuevo disco duro al servidor y lo creamos en ceph -> OSD -> crear
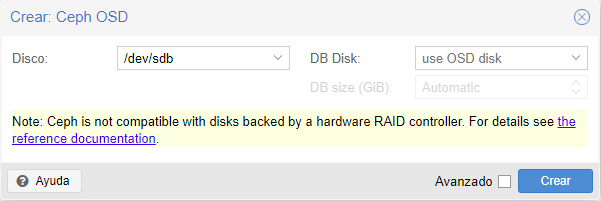
Una vez añadidos todos los OSD veremos que si recargamos la web, en todos los nodos nos sale que esta up.
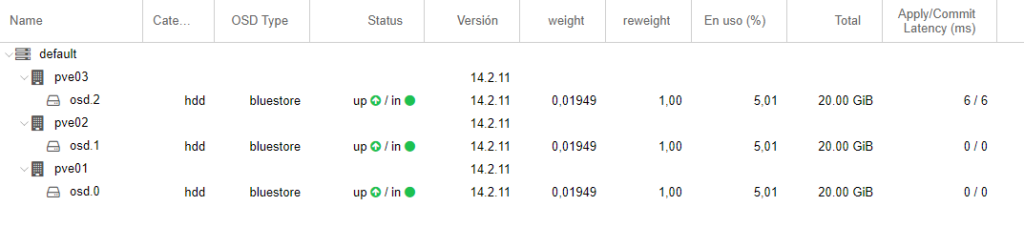
Si vamos a centro de datos -> ceph, veremos que marca en verde que todo esta up
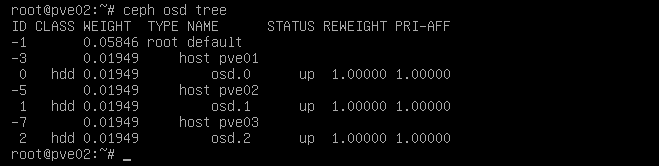
Verificar OSD des de la consola:
Para verificar el estado de los OSD des de la consola lo podemos hacer con el comando ceph osd tree
Últimos retoques:
En mi caso con el mismo pool de ceph, en el almacenamiento del cluster de proxmox «centro de datos» he creado 2 datastores, uno para vms y el otro para containers para tenerlo todo mas ordenado.

Una vez que tenemos el datastore ceph configurados será la hora de hacer pruebas y crear VMS.
Creación de VM sobre datastore NFS -> próxima entrada.
Creación de VM sobre datastore ceph.
Para crear una vm sobre el almacenamiento de ceph, en el paso «Disco duro» al crear la vm en almacenamiento tendremos que seleccionar el ceph.
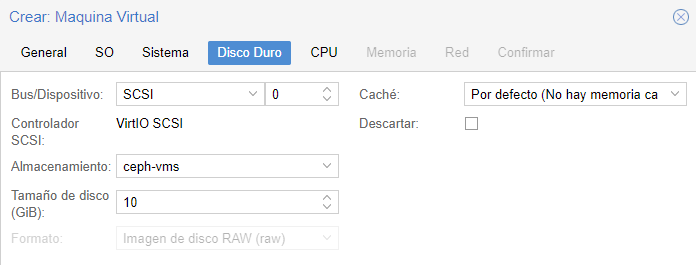
En el caso de querer crear un contenedor también lo podemos crear sobre el storage de ceph.
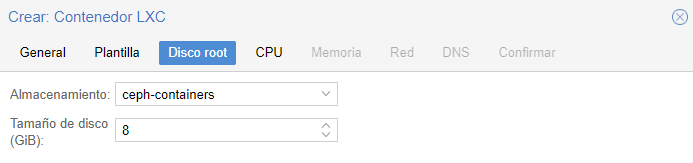
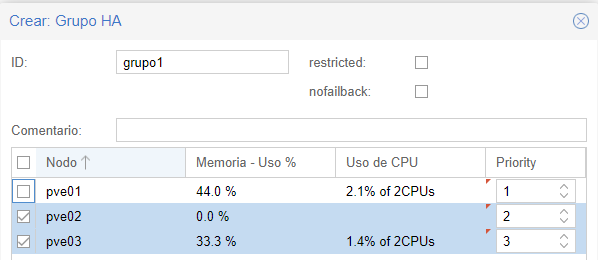
Configuración de alta disponibilidad:
Centro de datos -> HA -> grupos
Agregamos el contenedor creado al grupo de alta disponibilidad, para que en caso de caída de un nodo lo levante en otro nodo.
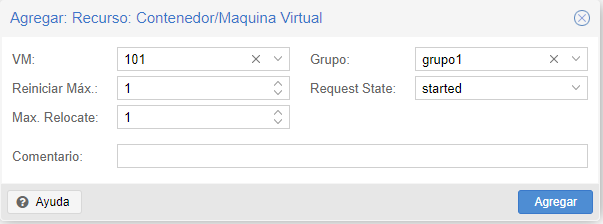
¿Qué pasa si el contenedor esta en el nodo 3 y por accidente cae el nodo?
Veremos como se migra automáticamente al nodo que esté disponible.
En este apartado veremos como ceph detecta que uno de los discos ha caído.
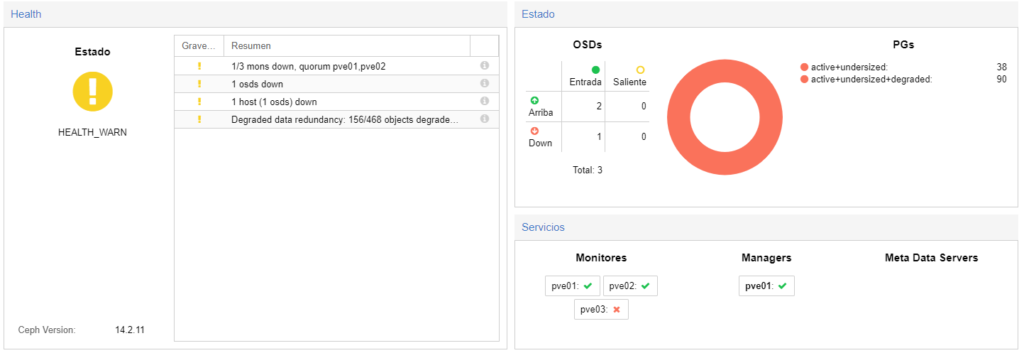
Proxmox detecta que ese nodo ha caído y recoloca el contenedor en otro nodo.

Veremos que el contenedor se vuelve a migrar correctamente a otro nodo.
¿Qué pasa si el nodo esta up pero el disco falla?
En este caso lo que haré es que eliminaré el disco de la maquina virtual de vmware para simular el fallo.
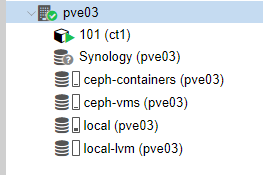
Monitorizamos en uno de los nodos los errores de ceph con:
ceph -w

A su vez también lo podremos ver des de proxmox
A pesar de todo puedo seguir accediendo al contenedor aunque en ese mismo nodo ha caído el OSD.
Para simular la recuperación, lo que haré es añadir un disco nuevo.
He añadido el disco nuevo y he reiniciado el nodo de proxmox ya que al ser virtualizado no puedo añadir y quitar discos en caliente.

Verificamos los OSD en ceph y veremos que el del nodo3 esta caído.
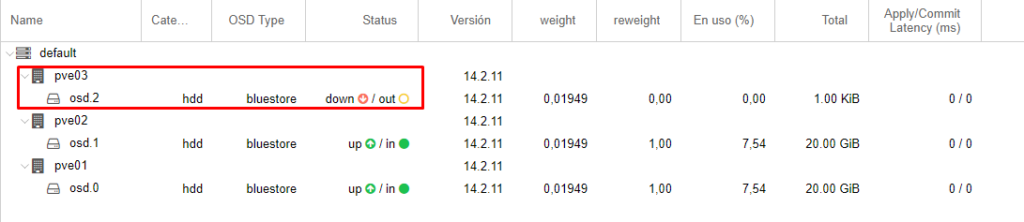
Lo que haré es crear un nuevo OSD con el disco nuevo del mismo tamaño.
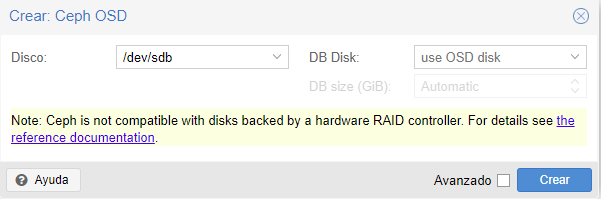
Veremos en el nodo 1 con ceph -w que ya ha detectado en nuevo OSD.

Y veremos que poco a poco va reconstruyendo el cluster de ceph con el nuevo disco y sincronizando los objectos y sin que el contenedor haya caído.
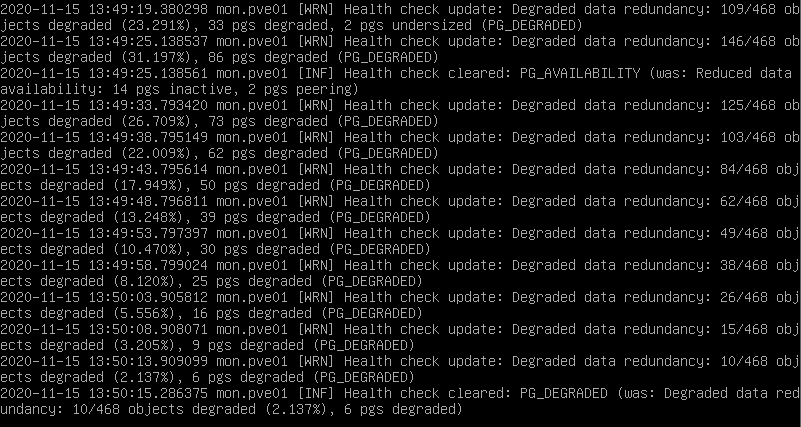
Veremos como poco a poco irá reconstruyendo el cluster.
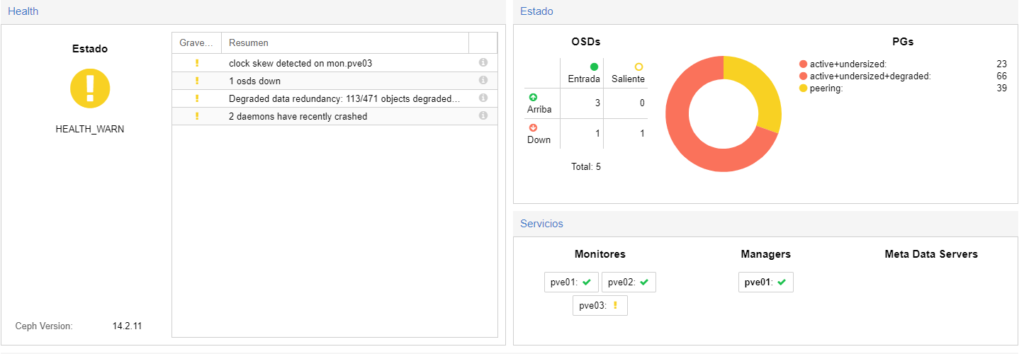
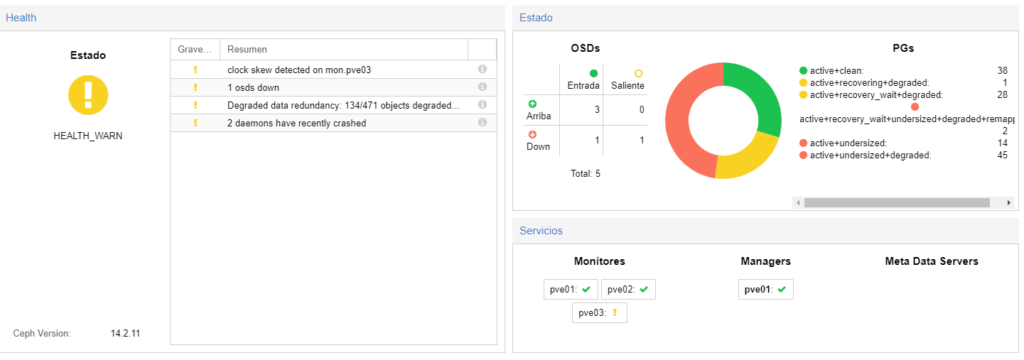
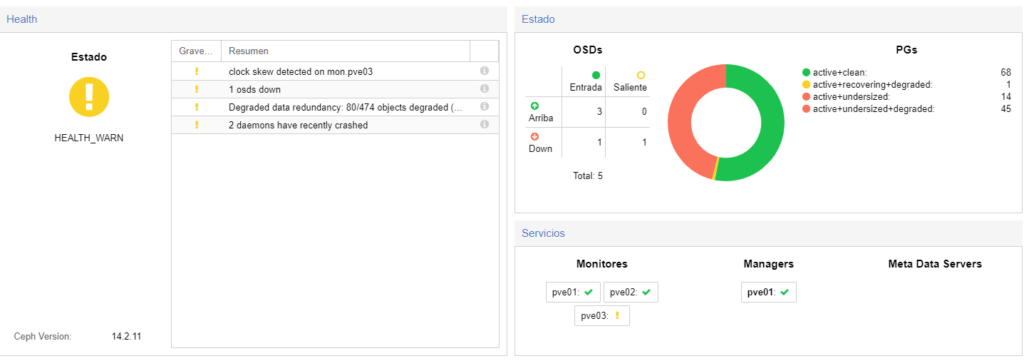
Aún así al tener 2 OSD caídos, lo que he hecho es añadirle 2 más, así hay 4 disponibles y 2 caídos con lo cual no habrá problema de datos.
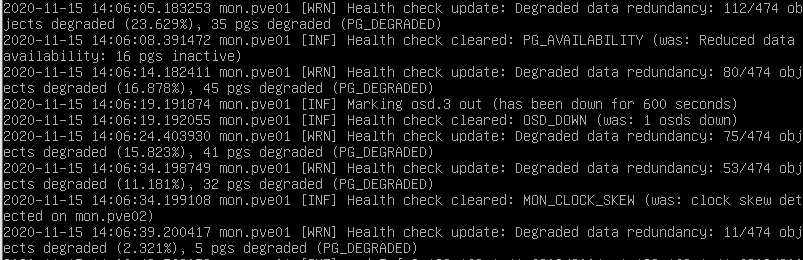
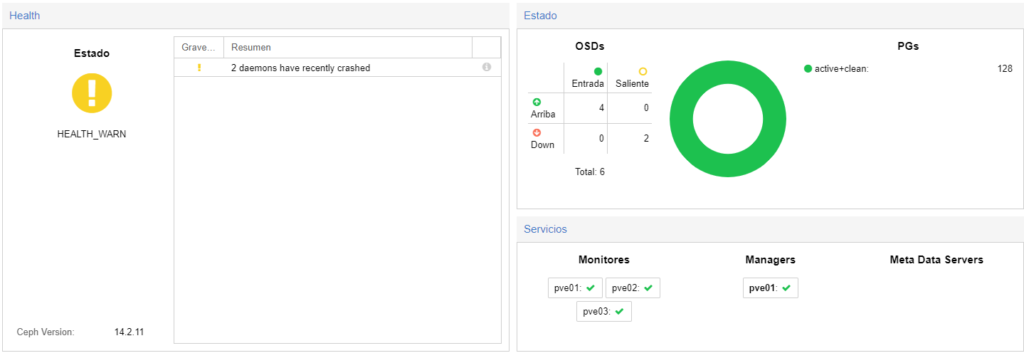
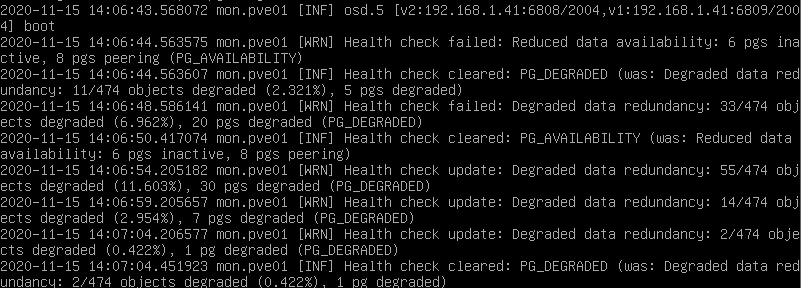
Veremos que queda un 0.422% para que se acabe de reconstruir, pero no lo acaba de hacer del todo correctamente. Por otro lado lo que haré es los OSD que en teoría he simulado que fallaban los voy a borrar.
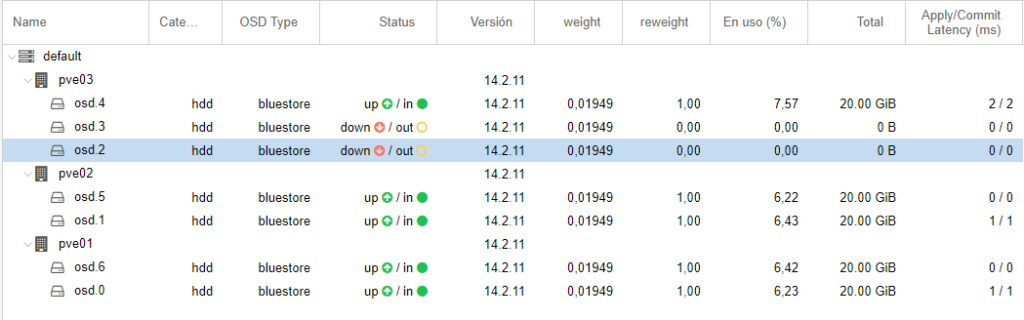
Finalmente quedaría algo así:
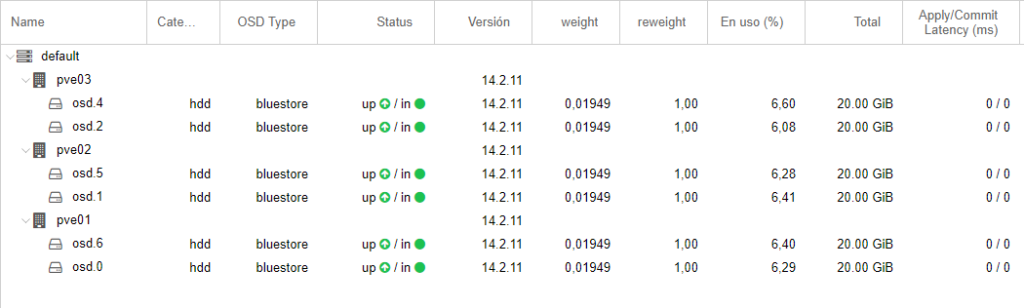
Espero que os haya gustado el post. ¡Hasta la próxima!
Saludos Aderic:
Muy bien explicado todo, perdona que sea ahora mi comentario , es que recién me inicio en proxmox y buscando algo para aprender sobre ceph me encontré con este escrito tuyo, te digo que me resulto de mucha utilidad sobre todo tu exlicacion cuando se cae un nodo o falla un disco , como se reconstruye por ceph todo, es algo impresionante.
Gracias
Buenas Orlando,
Muchas gracias por tu comentario y encantado de que te haya podido ayudar este post.
Un saludo 🙂
Excelente explicacion una pregunta monte un cluster virtualizado pero me di cuenta que si se cae el nodo que tiene el cluster nada funciona hay manera de eso ponerlo en HA?
Buenas Cesar,
El cluster virtualizado entiendo que te refieres a montar 3 vm de proxmox sobre vmware/virtualbox o 3 servidores físicos con proxmox instalado?
Un saludo!
Muy bueno el post. Con el unico que me he enterado del tema. Muchas gracias. Lo que no se aun es el tema de hacer disco compartido, no me queda claro es el tema de «Añadir recurso NFS centralizado al cluster de proxmox», lo que pone es «Export» no entiendo de donde sale. Gracias si me lo pudieras aclarar.
Buenas Fede,
El parámetro export sale de la ruta del servidor nfs que es lo que se esta utilizando en este caso, en este post lo hice con un synology de test, donde puedes crear carpetas y compartirlas por nfs y en export es la ruta donde esta el recurso compartido. En caso de hacerlo con debian 11 por ejemplo la ruta que pondras en proxmox es la ruta configurada en /etc/exports.
UN saludo.
Buenos dias, antes de nada agradecer toda la explicacion de los procesos. Tengo un duda realizando las pruebas antes de lanzar a producion, He quitado un nodo, transcurrido un tiempo solo tengo acceso por SSH ¿ como se sustitiuria un nodo que ha fallado y no es accesible (por fallo de placa, robo… ) si ha transcurrido un tiempo y no puedo acceder via web a su gestion?
Buenos días Fernando,
No me queda claro a que te refieres con «He quitado un nodo, transcurrido un tiempo solo tengo acceso por SSH». Me faltaría algo mas de información. No se si te refieres a quitar un nodo del clúster y éste nodo es el que solo tienes acceso por ssh o que al quitar un nodo del clúster, el clúster solo puedes acceder por ssh y pierdes gestión web.
Un saludo.
Saludos muy buena tu explicacion, actualmente estoy restructurando un ambiente que tenia con alta disponibilidad proxmox, son 3 nodos, 2 nodos con 40 tb y un nodo con 20 tb, existe algun problema que los 3 nodos no tengan el mismo tamaño de almacenamiento ?
Saludos,
El único problema que vería es que si estan los nodos en alta disponibilidad y con la configuración de que cuando cae un nodo completo se migren las vm en otro nodo hay que mirar que el espacio en disco sea el correcto, ya que tiene que tener espacio suficiente para mantener la caída de los nodos configurados si es que así lo tienes configurado. Por otra parte si estan dentro de ceph (segun mi opinion) no se si hay problema ya que ceph coje todos los osd de los nodos y los convierte en espacio compartido, claro está que tendrias que tenerlo añadido como almacenamiento compartido dentro de cada nodo en el proxmox.